


suivant: Méthodologie expérimentale
monter: Expériences numériques
précédent: Expériences numériques
Table des matières
D'un point de vue pratique, les expériences numériques ont pour la plupart été réalisées avec une matrice de nudging facile et rapide à implémenter:
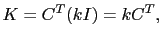 |
(3.11) |
où 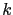 est un c
est un c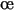 fficient scalaire de gain, et
fficient scalaire de gain, et 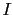 est la matrice identité de l'espace des observations. Ce choix est motivé par plusieurs remarques. Premièrement, les matrices de covariance telles que
est la matrice identité de l'espace des observations. Ce choix est motivé par plusieurs remarques. Premièrement, les matrices de covariance telles que 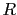 sont généralement mal déterminées. Par ailleurs, ce choix est extrêmement simple et ne nécessite pas d'appliquer une méthode d'estimation de paramètres. Enfin, le choix naturel de la matrice de nudging est
sont généralement mal déterminées. Par ailleurs, ce choix est extrêmement simple et ne nécessite pas d'appliquer une méthode d'estimation de paramètres. Enfin, le choix naturel de la matrice de nudging est 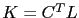 où
où 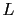 est un opérateur linéaire sur l'espace des observations. En effet, si les observations ne sont pas localisées aux points du maillage, la matrice
est un opérateur linéaire sur l'espace des observations. En effet, si les observations ne sont pas localisées aux points du maillage, la matrice 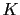 aura le rôle de ramener la correction
aura le rôle de ramener la correction
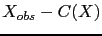 des points d'observation vers les points du maillage.
des points d'observation vers les points du maillage.
De même, pour la matrice rétrograde, nous choisissons généralement
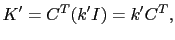 |
(3.12) |
comme dans le cas direct. Ce choix est également motivé par la simplicité et la rapidité de notre méthode dans ce cas là.
Les deux uniques paramètres de cette méthode deviennent alors les scalaires
et 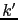 . Le scalaire
. Le scalaire 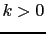 est généralement fixé de sorte que le terme de nudging soit petit par rapport aux termes du modèle afin de respecter le compromis entre le modèle et les observations. Le scalaire
est généralement fixé de sorte que le terme de nudging soit petit par rapport aux termes du modèle afin de respecter le compromis entre le modèle et les observations. Le scalaire 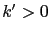 est quant à lui choisi comme étant le plus petit cfficient qui stabilise la résolution numérique de l'équation rétrograde.
est quant à lui choisi comme étant le plus petit cfficient qui stabilise la résolution numérique de l'équation rétrograde.
suivant: Méthodologie expérimentale
monter: Expériences numériques
précédent: Expériences numériques
Table des matières
Retour à la page principale