Concernant la matrice de nudging direct, la méthode ayant été beaucoup étudiée et utilisée dans les ![]() dernières années [70,110,104,103], il existe plusieurs possibilités pour fixer la matrice
dernières années [70,110,104,103], il existe plusieurs possibilités pour fixer la matrice ![]() de nudging direct. La plus connue est la méthode du nudging optimal, permettant de déterminer les c
de nudging direct. La plus connue est la méthode du nudging optimal, permettant de déterminer les c![]() fficients optimaux grâce à une méthode variationnelle d'estimation de paramètres [120,113].
fficients optimaux grâce à une méthode variationnelle d'estimation de paramètres [120,113].
Nous pouvons déjà noter qu'imposer ![]() dans (3.2) nous ramène aux équations du modèle (3.1). D'un autre côté, imposer
dans (3.2) nous ramène aux équations du modèle (3.1). D'un autre côté, imposer ![]() revient à substituer les observations à la trajectoire du modèle à chaque instant d'observation. L'un comme l'autre ont l'inconvénient de privilégier l'une des deux sources d'information (modèle et données) aux dépens de l'autre.
revient à substituer les observations à la trajectoire du modèle à chaque instant d'observation. L'un comme l'autre ont l'inconvénient de privilégier l'une des deux sources d'information (modèle et données) aux dépens de l'autre.
Soit ![]() la matrice de covariance des erreurs d'observation. Cette matrice intervient dans les méthodes classiques d'assimilation de données, aussi bien variationnelles (3D-VAR, 4D-VAR, 4D-PSAS, ...) que séquentielles (filtres dérivés du filtre de Kalman) [54,61,91,66,67]. En pratique, on ne connaît pas exactement les statistiques d'erreur, et on considère donc une approximation de cette matrice, qu'on suppose symétrique définie positive.
la matrice de covariance des erreurs d'observation. Cette matrice intervient dans les méthodes classiques d'assimilation de données, aussi bien variationnelles (3D-VAR, 4D-VAR, 4D-PSAS, ...) que séquentielles (filtres dérivés du filtre de Kalman) [54,61,91,66,67]. En pratique, on ne connaît pas exactement les statistiques d'erreur, et on considère donc une approximation de cette matrice, qu'on suppose symétrique définie positive.
On suppose ici que le modèle est linéaire, i.e. que ![]() est un opérateur linéaire. On suppose également que
est un opérateur linéaire. On suppose également que ![]() représente un opérateur symétrique. Une discrétisation temporelle classique (méthode d'Euler implicite) de l'équation (3.2) est la suivante:
représente un opérateur symétrique. Une discrétisation temporelle classique (méthode d'Euler implicite) de l'équation (3.2) est la suivante:
En choisissant
| (3.8) |
Comme conséquence directe, nous constatons qu'il n'y a aucune nécessité d'introduire un terme supplémentaire de régularisation, comme c'est le cas dans le 4D-VAR avec un terme de rappel à une ébauche de la condition initiale. Dans l'algorithme BFN, il suffit d'initialiser avec l'ébauche, sans besoin d'avoir une information sur ses statistiques d'erreur, et sans la prendre en considération dans le reste de l'algorithme.
Le BFN fournit automatiquement une correction du modèle grâce aux observations, et le modèle est alors une contrainte faible. L'énorme avantage est que cette méthode est moins sensible au fait que le modèle théorique ne modélise pas forcément bien la réalité.
À noter que dans les cas non linéaires, le terme
![]() de l'équation (3.9) peut être remplacé par un terme
de l'équation (3.9) peut être remplacé par un terme ![]() , où
, où ![]() est l'énergie du système à l'équilibre.
est l'énergie du système à l'équilibre.
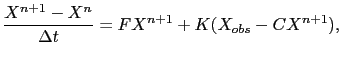
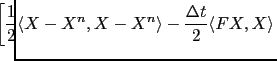
![$\displaystyle \hspace*{-0.5cm} + \left. \frac{\Delta t}{2} \langle R^{-1}(X_{obs}-CX),X_{obs}-CX\rangle \right].$](img248.png)