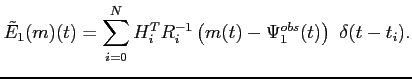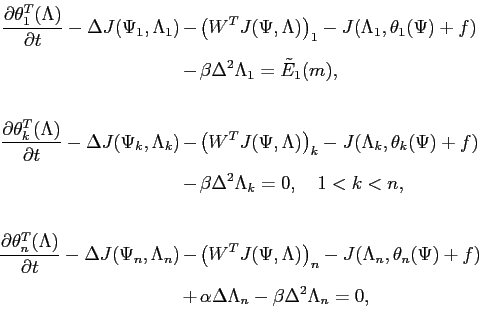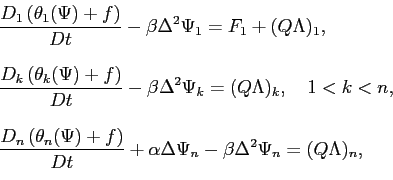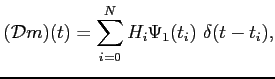


suivant: Résultats numériques
monter: Algorithme dual
précédent: Lien avec la méthode
Table des matières
Voyons maintenant comment l'algorithme dual peut être utilisé dans
le cas d'un modèle non linéaire, le modèle quasi-géostrophique
barocline. Nous rappelons qu'un des avantages de la méthode duale est
qu'elle couvre aussi la méthode primale dans un cadre linéaire. En
effet, la méthode duale agit sur les matrices de covariance d'erreur directes et
en faisant tendre la matrice de covariance d'erreur modèle vers zéro,
la méthode n'est pas perturbée et devient équivalente à la
méthode primale pour un problème sans erreur modèle.
Du fait de la non linéarité du modèle, la trajectoire
utilisée pour linéariser le modèle autour d'un
état de référence évolue ici à chaque itération, et nous
avons donc abandonné l'écriture sous forme incrémentale
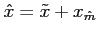
. Nous devons donc construire un
nouvel algorithme dual pour notre modèle qui consiste à
calculer une fonction coût duale de la fonctionnelle primale (comme
indiqué dans le paragraphe 2.2 du chapitre 2) via une linéarisation
adéquate autour d'un état de référence. La difficulté
majeure de l'algorithme dual vient du fait que la trajectoire utilisée
pour linéariser le modèle est réactualisée à chaque itération,
et par conséquent, les opérateurs d'observation linéarisés et
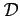
aussi. La fonction coût duale change donc aussi à chaque itération
dans le processus de minimisation.
L'algorithme dans
le cas non linéaire se présente
sous la forme suivante :
Une fois l'opérateur
construit, il ne reste plus qu'à
utiliser la théorie vue précédemment pour définir la
fonction coût duale :
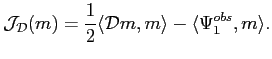 |
(5.39) |
La fonctionnelle
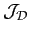
mesure l'écart entre
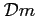
et
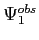
,
c'est-à-dire entre la trace dans l'espace des observations de la solution
du modèle direct et le vecteur des observations du système.
Comme l'opérateur
est linéaire symétrique défini positif,
la gradient de
est immédiat :
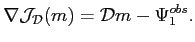 |
(5.40) |
Nous avons maintenant tout ce qu'il faut pour appliquer un algorithme
de minimisation de la fonction
coût duale
, en utilisant simplement une méthode itérative de type
quasi-Newton comme par exemple un algorithme L-BFGS, et en réactualisant
à chaque itération la fonction coût duale avec la nouvelle ébauche obtenue.
En supposant le minimum
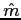
identifié, il est alors facile de reconstruire la
trajectoire correspondante dans l'espace des états : il suffit de
résoudre les équations (
5.35) et
(
5.36), la condition initiale dans l'espace des
états étant donné par la formule (
5.37).
On observe à nouveau que la fonctionnelle duale est définie sur un
espace (celui des observations) de dimension plus petite que la
fonctionnelle primale (définie sur l'espace des états). La
minimisation de la fonctionnelle duale ne coûte donc pas plus
cher que la minimisation de la fonctionnelle primale. De plus, cet algorithme
tient toujours compte de l'erreur modèle, ce qui était
numériquement impossible avec l'approche primale du 4D-VAR.
suivant: Résultats numériques
monter: Algorithme dual
précédent: Lien avec la méthode
Table des matières
Retour à la page principale