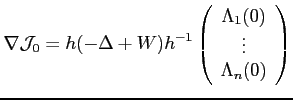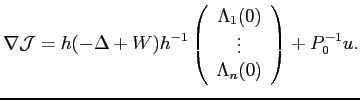Le gradient de la première partie (notée
![]() ) de la
fonctionnelle
) de la
fonctionnelle
![]() s'obtient en résolvant les équations
(5.12-5.14) avec comme condition finale la
nullité des fonctions de courant duales. On obtient alors :
s'obtient en résolvant les équations
(5.12-5.14) avec comme condition finale la
nullité des fonctions de courant duales. On obtient alors :
Le gradient de la seconde partie de
![]() s'obtient simplement par
dérivation par rapport à
s'obtient simplement par
dérivation par rapport à ![]() . On a alors :
. On a alors :
La minimisation effective de la fonction coût
![]() se fait en utilisant
une méthode L-BFGS.
se fait en utilisant
une méthode L-BFGS.