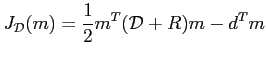À ce jour, le principal inconvénient du 4D-VAR (et de sa version
incrémentale) est qu'il suppose le modèle parfait, et il ne peut
à aucun moment prendre en compte une erreur modèle. En effet, cela
reviendrait à rajouter un terme inconnu, dépendant du temps, au
modèle direct (ainsi qu'au linéaire tangent et à l'adjoint). Il
faudrait ensuite ajouter ces termes au vecteur de contrôle, et le
problème de minimisation serait alors très délicat à
résoudre, sa taille pouvant facilement dépasser ![]() . En effet,
même si le nombre d'itérations à effectuer dans l'algorithme
de minimisation est indépendant de la taille du problème, le coût
de chaque itération augmente.
. En effet,
même si le nombre d'itérations à effectuer dans l'algorithme
de minimisation est indépendant de la taille du problème, le coût
de chaque itération augmente.
L'algorithme 4D-PSAS, encore appelé algorithme dual, permet de
prendre en compte de façon inhérente l'erreur modèle ([4],
[5], [1], [9], [33], [32]). Nous
allons expliquer sommairement son principe, car nous reviendrons
dessus en détail dans le chapitre ![]() .
.
Rajoutons une erreur dans le modèle discrétisé :
Il faut définir une nouvelle fonction coût, intégrant les erreurs modèle :
Comme nous l'avons précédemment vu, il est difficile de minimiser une telle fonction, simplement au vu de la taille et du nombre des vecteurs inconnus.
Plaçons nous dans une optique lagrangienne, où l'on chercherait
à minimiser la fonctionnelle ![]() précédente. En écriture
incrémentale, on peut définir le lagrangien suivant :
précédente. En écriture
incrémentale, on peut définir le lagrangien suivant :
Le modèle apparaît désormais comme une contrainte faible et n'est plus une contrainte forte comme dans le 4D-VAR. On a la propriété suivante (voir [43] pour les problèmes de min-max et d'optimisation sous contrainte) :
Il ne reste plus qu'à changer l'écriture de (2.32) pour obtenir un problème de maximisation (de la fonctionnelle duale), équivalent au problème de minimisation de la fonctionnelle primale (2.30) :
Il faut noter que la réécriture du problème consistant à minimiser la fonctionnelle
![]() sous forme d'un problème de min-max ainsi que la réécriture duale du problème
ne nécessite pas que le problème soit linéaire, toute cette théorie reste
valable lorsque le problème est convexe.
sous forme d'un problème de min-max ainsi que la réécriture duale du problème
ne nécessite pas que le problème soit linéaire, toute cette théorie reste
valable lorsque le problème est convexe.
Quitte à changer le signe du résultat, on se ramène à devoir minimiser la fonctionnelle duale suivante :
Sous forme matricielle, cela peut s'écrire
L'autre point intéressant de cet algorithme est que le vecteur de
contrôle dual (![]() ) appartient à l'espace des observations qui est
de dimension souvent
) appartient à l'espace des observations qui est
de dimension souvent ![]() fois plus petite que l'espace des états
pour la fonctionnelle primale. En effet, pour un modèle
opérationnel, la dimension du vecteur d'état est compris entre
fois plus petite que l'espace des états
pour la fonctionnelle primale. En effet, pour un modèle
opérationnel, la dimension du vecteur d'état est compris entre
![]() et
et ![]() alors que les observations utilisables sont en
général de l'ordre de
alors que les observations utilisables sont en
général de l'ordre de ![]() pour les périodes d'assimilation
usuelles. La minimisation intervient donc sur un espace plus petit, il
est donc possible d'obtenir de meilleurs résultats pour un nombre
comparable d'itérations dans l'algorithme de descente. En effet, chaque
itération dans la minimisation a globalement le même coût que
pour le 4D-VAR puisque le conditionnement du problème est sensiblement
le même, mais pour le même coût, le 4D-PSAS prend en compte
l'erreur modèle.
pour les périodes d'assimilation
usuelles. La minimisation intervient donc sur un espace plus petit, il
est donc possible d'obtenir de meilleurs résultats pour un nombre
comparable d'itérations dans l'algorithme de descente. En effet, chaque
itération dans la minimisation a globalement le même coût que
pour le 4D-VAR puisque le conditionnement du problème est sensiblement
le même, mais pour le même coût, le 4D-PSAS prend en compte
l'erreur modèle.
Enfin, l'algorithme dual utilise le modèle comme une contrainte faible,
mais il suffit de faire tendre les erreurs modèle
![]() vers
0
pour retrouver à la limite l'algorithme primal (4D-VAR) à contrainte
forte. Ce passage à la limite ne pose aucune difficulté puisque le 4D-PSAS utilise les
matrices de covariance directes (et non leurs inverses comme dans le cas
du 4D-VAR).
vers
0
pour retrouver à la limite l'algorithme primal (4D-VAR) à contrainte
forte. Ce passage à la limite ne pose aucune difficulté puisque le 4D-PSAS utilise les
matrices de covariance directes (et non leurs inverses comme dans le cas
du 4D-VAR).
Le 4D-PSAS est donc une alternative intéressante au 4D-VAR puisqu'il
conduit, en théorie, aux mêmes résultats, mais l'algorithme dual
est le seul qui permet en pratique en prendre en compte l'erreur
modèle. Pour ces raisons, cet algorithme est probablement celui qui
devrait équiper prochainement les centres européens de prévision
météo.
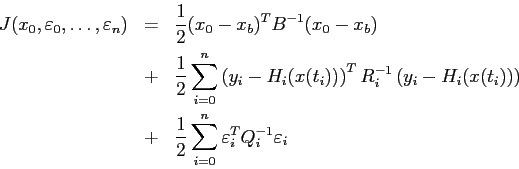
![\begin{displaymath}\begin{array}{rcl} \mathcal{L}(\delta x_0,(\varepsilon_i)_{0\...
..._i\delta x_0 + \tilde{\varepsilon}_i) \right] . m_i \end{array}\end{displaymath}](img156.png)
![\begin{displaymath}\begin{array}{rl} & \displaystyle \min_{\delta x_0,(\varepsil...
...athcal{D}\left( (m_i)_{0\le i\le n} \right) \right] \end{array}\end{displaymath}](img164.png)
![\begin{displaymath}\begin{array}{rcl} J_\mathcal{D}\left( (m_i)_{0\le i\le n}\ri...
...] [0.5cm] &-& \displaystyle \sum_{i=0}^n d_i.m_i \end{array}\end{displaymath}](img165.png)